AI in the industry: training models with small datasets
Common practices for training machine learning models are based on large datasets, but these are often not available in the manufacturing industry. Data-centric AI is a new approach that should also enable manufacturing companies to successfully use AI systems.

The use of artificial intelligence (AI) in business is growing and offers enormous potential for optimising business processes and for new and innovative business models. The wealth of potential offered by AI is impressively demonstrated time and again by tech giants like Google, Apple or Meta (formerly Facebook), in particular. And not surprisingly: such platform giants and large corporations have access to almost inexhaustible data sources – common deep learning algorithms achieve excellent results under these conditions. All hail big data!

How AI agents are revolutionising our working world

Data, data, data! The secret to successful use of AI in your SME

“The real AI hype is yet to come”

How China protects its data
The reality is somewhat different, however, in many sectors and companies: They do not have vast amounts of data at their disposal to sufficiently feed existing machine learning models and to be able to use them beneficially. This often applies to manufacturing companies too: “AI poses very specific challenges for the industry”, notes Francesco Spadafora, Software Engineer at bbv in the area of embedded applications. “Only small datasets are often available and the costs of equipping machinery with additional sensors is very high; or the quality of the available data is not good enough to properly train machine learning models.”
For example, if AI is to be used to detect production defects, training the algorithm becomes a Herculean task. Because product defects are rare, most manufacturers do not have millions, thousands or even hundreds of examples of a specific error type that has to be eradicated. In addition, the effort required to generate more data can be significant.
“Data-centric AI”: Quality not quantity
Andrew Ng recognised the challenges that manufacturing companies have to face in introducing AI methods. Ng is one of the most prominent figures in the AI sector: He was one of the founders and leader of the Google Brain project for deep learning techniques, worked with the Chinese search engine company Baidu and in his current role as CEO of his start-up Landing AI is fully committed to implementing AI projects in the industrial sector. He also saw that the AI practices of big tech corporations cannot be transferred one-to-one to the manufacturing industry.
Ng therefore advocates “data-centric AI” – a data-focused approach to training machine learning models. Instead of trying to optimise these for the existing dataset, the starting point here is quite different: Some models are defined in advance with parameters. Their predictions are then deliberately used in the data-centric analysis in order to increase the quality of the data. The data-centric AI approach therefore aims to develop AI systems with high-quality data. According to Ng, data-centric AI has already proven its worth in practice: A significant reduction in the time needed to implement AI applications as well as better data yield and precision can be attributed to the approach.
But, how do you optimise your data for the machine learning models that are to be used? bbv follows the data-centric AI approach in this respect, but starts with the business requirements:
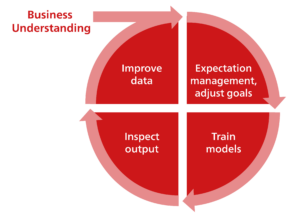
The four phases of the development model are explained below.
Business Understanding
Similar to the CRISP DM model, the data-centric AI approach also requires a basic business understanding and domain knowledge to begin with. How does my company make money? What are the challenges in production? These questions are pivotal for a purposeful AI solution, especially in the manufacturing sector. “Many more discussions are needed in industry about one’s own business model and the added value of AI-controlled processes than in digital corporations”, says Cedric Klinkert, Embedded Software Engineer at bbv. “The initial effort involved in capturing data is high in the industry – especially when a solid data strategy is not yet in place and additional sensors are required. This also often means that you only have small datasets to work with.”
Expectation management & adjust goals
The next step is to clarify which problems should actually be addressed with the AI solution. Several iterations are necessary here sometimes before really realistic business goals have been formulated. “According to a study by Gartner from 2017, 85 percent of data science projects fail – often because companies expect too much from them”, says Spadafora. “You have to talk to all stakeholders, calibrate and prioritise expectations and work towards creating an infrastructure that allows you to collect the right data.”
Train models
Based on the problem to be solved with AI, we propose defining a handful of models. These will not be changed over the course of the process. In this step, they are trained using appropriate methods and evaluated using suitable metrics.
Inspect models (output)
Results are scrutinised based on AI training and the data used is inspected. It is worthwhile here to take a closer look again at marginal cases, outliers or incorrectly classified data. This should be done ideally by visual inspection and qualitative analysis. These findings serve as the basis for the next step.
Improve data
The data is reprocessed based on the findings. New and targeted data can also be consulted to cover the missing aspects. Domain knowledge is likewise required here in order to prepare the available raw data properly and extract the features that can be used to improve the AI system (feature engineering). “Precisely because only smaller datasets are used, they can be analysed and optimised in detail”, states Cedric Klinkert.
Engaging with the topic through innovation workshops
Thanks to data-centric AI, even smaller companies are in a position to implement successful AI cases – because the iterative approach is aimed precisely at starting with a small amount of data and only adding new data that is actually relevant for the business case in question when necessary. But what does this look like?bbv has many years of experience implementing embedded systems and IoT projects – and know-how in machine learning: “Our innovation workshops are also suitable for determining the expectations of customers and highlighting initial action areas for AI”, says Francesco Spadafora. “With the domain knowledge of the customer and our expertise in generating new and, above all, correct data we also help the customer at the next stage of implementation – from initial proof of concept to comprehensive business case.”

The expert
Francesco Spadafora
Francesco Spadafora is a Software Engineer at bbv in the area of embedded applications in the industry and medical technology fields. During his studies, he worked on analysing data from sensor networks. Since then he believes that the next step in innovation is to gain a better understanding of systems and processes based on insights from data.

The expert
Cedric Klinkert
Dr. Cedric Klinkert is a Software Engineer at bbv in the area of embedded applications in the industry and medical technology fields. His doctoral thesis involved researching new types of materials for transistors with the aid of computationally-intensive high-throughput simulations. When analysing this data, he took an in-depth look at machine learning methods. The insights gained strengthened his conviction that AI illustrates new perspectives of systems that need to be exploited.
Data Science Innovation Workshop
With our three-part workshop, you can assess the potential and risks in the field of data science faster and better. We support you individually with our process, method, technology and business expertise. Together we develop the most promising ideas into a resilient business case so that they can be implemented directly.
Data Science